This blog is an excerpt from the book chapter:
Web Analytics Overview. In Encyclopedia of Information Science and Technology, 3rd Edition.
Web Analytics Overview. In Encyclopedia of Information Science and Technology, 3rd Edition.
The fundamental goal of web analytics is to collect and analyze web traffic and usage patterns. A common way to study this data is to use the dimensional model. Under this model, there are two major types of data: facts or measurement data and dimensional data that describe facts from different aspects and levels. Facts data are mainly about usage count and time. The most basic measure is a page view, which is a single request for a web page. Count of user actions such as mouse clicks can also be used as a measure. Various metrics are calculated based on basic measures and dimensions. Dimensional data are much more complex. Major types of dimensions include time, content, location, user client information (such as operating system, browser type, screen size, etc.), and user or session.
Both measurement data and dimensional data come from a number of sources, which can be categorized into the following 4 types:
- Direct HTTP request data
- Application level data sent with HTTP requests
- Network level and server generated data associated with HTTP requests.
- External data
Direct HTTP request data directly come from HTTP request messages. An HTTP request is a message sent by a web client (browser) to a web server to request a resource (a web page or a web page element like an image). Traditionally, web traffic measurement is directly based on web resource visits (commonly called page view). Then each request is further described by a number of dimensions, such as page, visitor, technology, etc. The format of the HTTP 1.1 request is specified in IETF RFC 2616. A typical HTTP request message is shown in the following Figure.
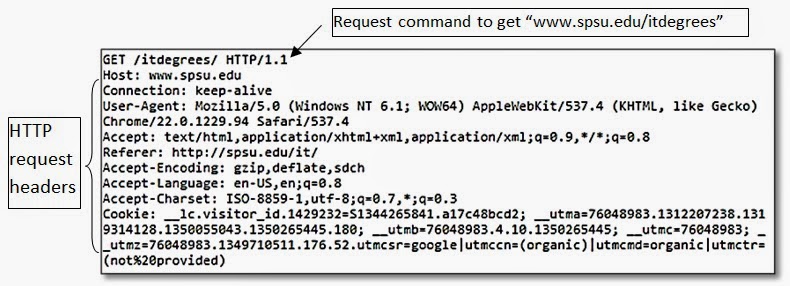
An HTTP request consists of a request command (the first line) and HTTP headers. The request command includes the required URI (unified resource identifier) information. A URI generally includes a host's domain or IP and a directory path. If the host information is not included as a part of the URI, then the “host” header has to be provided. The URI is the key information that leads to the count of a page/resource views. HTTP headers are pairs of field names and values. HTTP 1.1 specification defines a set of headers that can be included. These headers describe request and client characteristics. Most of the header data are dimensional type of data used in web analytics. Some commonly used header fields for tracking are:
· User-Agent field holds client information such as browser type and operating system type. This information can be used to profile client technologies.
· Referer (not “referrer”) field keeps the previously visited URL that leads to the current URL. This header can be used for the clickstream analysis where user visiting paths can be constructed by chaining a serial of requests. It also can be used for metrics like entry rate, exit rate, etc.
· Accept-Language field contains the list of natural languages that are preferred in the response. The list is determined based on the OS default locale. This can be used to track user’s language, e.g. en, en-US, es (Spanish), zh-cn (China).
· Cookie field holds application level information stored at the client side. This can hold various kinds of data that is beyond HTTP’s role, such as keyboard and mouse actions.
Application level data is generated and processed by application level programs (such as JavaScript, PHP, and ASP.Net). Some common examples are:
· Session data identify a client interaction with a website consisting of one or more related requests for definable unit of content in a defined time period. HTTP itself is stateless and cannot provide session information. Thus, this data is managed at the application level. Session data are usually sent as URL parameters or session cookies. They are important for calculate metrics like number of visits, time on site, number of page views per visit, etc.
· Referral data is different from the “referer” header in HTTP requests. HTTP referer is at the page request level and is usually a URL. Application level referral represents different sources leading to the current web resource and is usually a coded value. It can be used to analyze traffic levels from expected and unexpected sources, or to gauge channel effectiveness in advertisement tracking.
· User action data mainly include keyboard actions (e.g. user input of search terms) and mouse actions (e.g. cursor coordinates and movements). It also includes application specific action such as voting, playing of video/audio, bookmarking, etc.
· Client/browser side data include computer status information like display resolution and color depth, or any other information a user chooses to make available.
Application level data is usually embedded in HTTP requests. There are three common places to hold this information. First, they can be appended to a request URL as URL parameters. Server side programs can parse these parameters. For example, Google uses specifically constructed URLs in their search results to redirect users to the target while capturing extra information. Second, application data can be sent as the HTTP cookie header. Cookies are small text files that usually store user profile and activity data. The type of data that can be stored is directly determined by the client software and settings. Third, application data can also be included in the HTTP request body when an HTTP “POST” method is used (common for form submission).
Network level data is not part of an HTTP request, but it is required for successful request transmissions. The most prominent example is an IP address of a requestor. The requester's IP address and port number are required in order to return a response. This information is sent at the TCP/IP level and is logged by a web server. Server generated data is usually used for internal reference and is recorded in server log files. The log file commonly records file size, processing time, server IP, request events other than HTTP request, etc.
External data can be combined with on-site data to help interpret web usage. For example, IP addresses are usually associated with Geographic regions and internet service providers. Third party databases or services provide such mappings, e.g., MaxMind’s GeoIP and GeoLite (http://www.maxmind.com), IPInfoDB (http://ipinfodb.com), GeoBytes (http://www.geobytes.com), and hostip.info (http://www.hostip.info). Another example is user information that was collected and stored during a separate process (e.g. registration). If user identity information is required in a visit, then this profile data can be associated with usage data. Revenue and profit can be classified as external data if they can be associated with particular webpages. Search terms and advertisement keywords requests are also external data and are usually provided by third party services.
Web Analytic Major Data and Source Summary
Data
|
Type
|
Source
|
Page view
|
Measurement
|
HTTP request
|
Client profile/User-Agent (browser, OS)
|
Dimension
|
Application, HTTP request
|
User action (keyboard and mouse)
|
Measurement
|
Application
|
Geo location
|
Dimension
|
External
|
Visit or session
|
Measurement, dimension
|
Application
|
Referrer (preceding webpage)
|
Dimension
|
HTTP request (“referer” header)
|
Referral (channel identification)
|
Dimension
|
Application
|
Client profile (screen size, color depth)
|
Dimension
|
Application
|
IP address
|
Dimension
|
Network protocol
|
User profile
|
Dimension
|
External
|
Revenue or profit
|
Measurement
|
External
|
No comments:
Post a Comment